وقتی صحبت از همزمانی در مقابل موازی سازی به میان می آید، ممکن است آشکار باشد زیرا آنها به همان مفاهیم در اجرای برنامه های کامپیوتری در یک محیط چند رشته ای اشاره می کنند. خوب، پس از نگاهی به تعاریف آنها در فرهنگ لغت آکسفورد، ممکن است به این فکر کنید. با این حال، هنگامی که در رابطه با نحوه اجرای دستورالعمل های برنامه توسط CPU عمیق تر به این مفاهیم بروید، متوجه خواهید شد که همزمانی و موازی دو مفهوم متمایز هستند.
این مقاله عمیقتر به همزمانی و موازیسازی، نحوه تغییر آنها و نحوه همکاری آنها برای بهبود بهرهوری اجرای برنامه میپردازد. در نهایت، بحث خواهد شد که کدام دو استراتژی برای خراش دادن وب مناسبتر هستند. پس بیایید شروع کنیم.
اجرای همزمان چیست؟
ابتدا، برای سادهتر کردن کارها، با همزمانی در یک برنامه کاربردی که در یک پردازنده واحد اجرا میشود، شروع میکنیم. Dictionary.com همزمانی را به عنوان یک اقدام یا تلاش ترکیبی و وقوع رویدادهای همزمان تعریف می کند. با این حال، میتوان در مورد اجرای موازی بهعنوان همزمانی اجراها، همین را گفت، و بنابراین این تعریف در دنیای برنامهنویسی کامپیوتر تا حدودی گمراهکننده است. به عنوان مثال، میتوانید هنگام گوش دادن به موسیقی در Windows Media Player، یک مقاله وبلاگ را در مرورگر خود بخوانید. فرآیند دیگری در حال اجرا خواهد بود: دانلود یک فایل PDF از یک صفحه وب دیگر—همه این مثالها فرآیندهای جداگانه ای هستند. این نشان میدهد که دستورالعملهای یک برنامه باید قبل از اینکه CPU به برنامه بعدی منتقل شود، اجرا شوند.
در مقابل، اجرای همزمان مقدار کمی از هر فرآیند را تا زمانی که همه کامل شوند، جایگزین میکند.
در یک پردازنده واحد چند رشتهای. محیط اجرا، یک برنامه زمانی اجرا می شود که برنامه دیگری برای ورودی کاربر مسدود شده باشد. حال ممکن است بپرسید که محیط چند رشته ای چیست؟ این مجموعهای از رشتهها است که مستقل از یکدیگر اجرا میشوند—بیشتر در بخش بعدی. منظور ما از همزمانی در مثال های بالا این است که فرآیندها به صورت موازی اجرا نمی شوند.
در عوض، بیایید بگوییم که یک فرآیند نیاز به تکمیل یک عملیات ورودی/خروجی دارد، سپس سیستم عامل CPU را در حالی که عملیات I/O خود را کامل میکند، به فرآیند دیگری اختصاص میدهد. این رویه تا زمانی ادامه مییابد که همه فرآیندها اجرای خود را کامل کنند.
با این حال، از آنجایی که تعویض وظایف توسط سیستم عامل در یک نانو یا میکروثانیه اتفاق میافتد، زمانی که فرآیندها به صورت موازی اجرا میشوند، برای کاربر به نظر میرسد،
آیا یک Thread است؟
برخلاف اجرای متوالی، CPU ممکن است کل فرآیند/برنامه را یکجا با معماری های فعلی اجرا نکند. در عوض، اکثر کامپیوترها ممکن است کل فرآیند را به چندین مؤلفه سبک وزن تقسیم کنند که مستقل از یکدیگر به ترتیب دلخواه اجرا شوند. این اجزای سبک وزن هستند که رشته نامیده می شوند.
برای مثال، Google Docs ممکن است چندین رشته داشته باشد که به طور همزمان کار کنند. در حالی که یک رشته به طور خودکار کار شما را ذخیره می کند، دیگری ممکن است در پس زمینه اجرا شود و املا و دستور زبان را بررسی کند.
سیستم عامل ترتیب و اولویت بندی رشته ها را تعیین می کند، کدام یک به سیستم وابسته است.
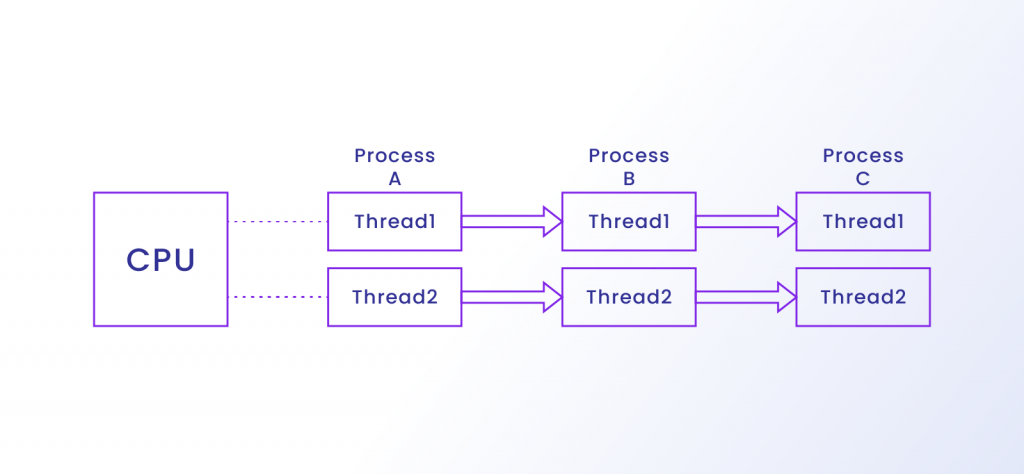
اجرای موازی چیست؟ در مقابل، کامپیوترهای مدرن بسیاری از فرآیندها را به طور همزمان در چندین CPU اجرا می کنند که به عنوان اجرای موازی شناخته می شود. بیشتر معماریهای فعلی چندین CPU دارند.
همانطور که در نمودار زیر مشاهده میکنید، CPU هر رشتهای را که به یک فرآیند تعلق دارد بهطور موازی با یکدیگر اجرا میکند.
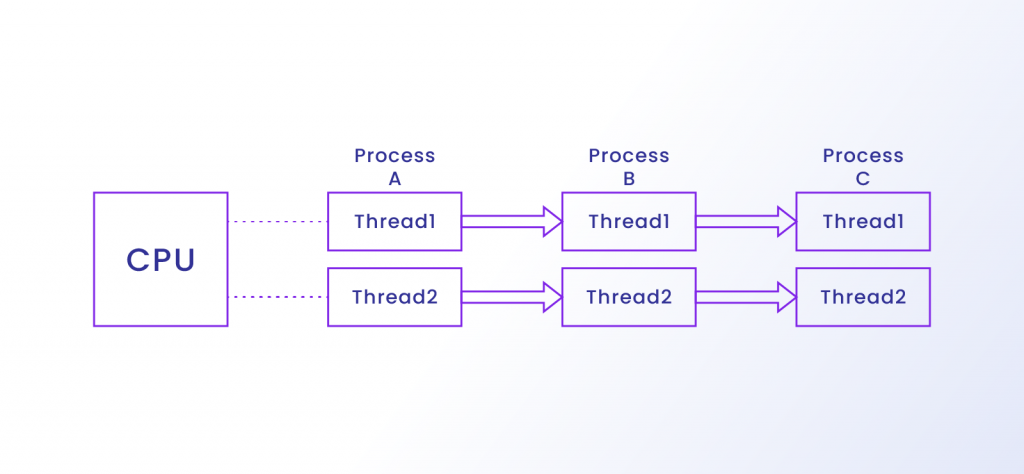
در موازی سازی، سیستم عامل رشته ها را به و از CPU در انشعابات ماکرو یا میکروثانیه بسته به معماری سیستم تغییر می دهد. برای اینکه سیستم عامل به اجرای موازی دست یابد، برنامه نویسان کامپیوتر از مفهومی به نام برنامه نویسی موازی استفاده می کنند. در برنامه نویسی موازی، برنامه نویسان کدی را برای بهترین استفاده از چندین CPU ایجاد می کنند.
چگونه همزمانی میتواند خراشهای وب را سرعت بخشد
با وجود دامنههای زیادی که از خراش دادن وب برای خراش دادن دادهها از وبسایتها استفاده میکنند، یک اشکال مهم زمانی است که برای خراش دادن مقادیر زیادی داده صرف میشود. اگر یک توسعهدهنده باتجربه نیستید، ممکن است در نهایت زمان زیادی را برای آزمایش تکنیکهای خاص تلف کنید قبل از اینکه در نهایت کد را بدون خطا و بهطور کامل اجرا کنید.
بخش زیر برخی از دلایل کندی اسکراپینگ وب را بیان میکند.[19659026]دلایل قابل توجهی برای اینکه چرا خراش دادن وب کند است؟
اولاً، اسکراپر باید به وب سایت مورد نظر در اسکراپینگ وب حرکت کند. سپس باید موجودیتها را از تگهای HTML که میخواهید از آنها پاک کنید، بکشد و بازیابی کند. در نهایت، در بیشتر شرایط، داده ها را در یک فایل خارجی مانند فرمت CSV ذخیره می کنید.
بنابراین همانطور که می بینید، اکثر وظایف فوق نیاز به عملیات ورودی/خروجی سنگین مانند کشیدن داده ها از وب سایت ها و سپس ذخیره آن در فایل های خارجی دارند. پیمایش به وبسایتهای هدف اغلب به عوامل خارجی مانند سرعت شبکه یا انتظار در هنگام در دسترس بودن شبکه بستگی دارد.
همانطور که در شکل زیر مشاهده میکنید، این مصرف بسیار آهسته زمان ممکن است فرآیند خراش دادن را در زمانی که مجبور به خراشیدن هستید، مختل کند. سه یا چند وب سایت فرض بر این است که شما عملیات تراشیدن را به صورت متوالی انجام دهید. ابتدا در بخش بعدی به موازیسازی نگاه میکنیم.
همزمانی در اسکراپینگ وب با استفاده از پایتون
مطمئن هستم که شما تا به حال یک نمای کلی از همزمانی و موازیسازی دارید. این بخش بر روی همزمانی در اسکرپینگ وب با یک مثال کد نویسی ساده در پایتون تمرکز خواهد کرد.
یک مثال ساده که بدون اجرای همزمان نشان می دهد
در این مثال، ما URL کشورها را با لیستی از شهرهای پایتخت بر اساس جمعیت از ویکی پدیا این برنامه لینک ها را ذخیره می کند و سپس به هر یک از 240 صفحه می رود و HTML آن صفحات را به صورت محلی ذخیره می کند.
برای نشان دادن اثرات همزمانی، ما دو برنامه را نشان خواهیم داد – یکی با اجرای متوالی و دیگری همزمان با چند رشته.
از واردات bs4 BeautifulSoup
از urllib.parse import urljoin
زمان واردات
def get_countries():
کشورها = 'https://en.wikipedia.org/wiki/List_of_national_capitals_by_population'
all_countries = []
پاسخ = requests.get(کشورها)
soup = BeautifulSoup (response.text، "html.parser")
country_pl = soup.select('th .flagicon+ a')
برای link_pl در country_pl:
پیوند = link_pl.get ("href")
پیوند = urljoin (کشورها، پیوند)
all_countries.append(لینک)
بازگشت همه_کشورها
def fetch(لینک):
res = requests.get(لینک)
با open(link.split("/")[-1]+".html، "wb") به صورت f:
f.write(res.content)
def main():
clinks = get_countries()
print(f"مجموع صفحات: {len(clinks)}")
start_time = time.time()
برای پیوند در کلیک ها:
واکشی لینک)
duration = time.time() – start_time
print(f"پیوندهای بارگیری شده {len(links)} در {دوره} ثانیه")
main()
توضیح کد
ابتدا، ما کتابخانهها، از جمله BeautifulSoap را برای استخراج دادههای HTML وارد میکنیم. کتابخانههای دیگر شامل درخواست دسترسی به وبسایت، urllib برای پیوستن به URLها همانطور که متوجه میشوید، و کتابخانه زمان برای یافتن کل زمان اجرای برنامه است.
درخواستهای واردات.
از واردات bs4 BeautifulSoup
از urllib.parse import urljoin
زمان واردات
برنامه ابتدا با ماژول اصلی شروع می شود که تابع get_countries() را فراخوانی می کند. سپس این تابع از طریق تجزیهکننده HTML به URL ویکیپدیا مشخصشده در متغیر کشورها از طریق نمونه BeautifulSoup دسترسی پیدا میکند.
سپس با استخراج مقدار در ویژگی href تگ anchor، URL را برای فهرست کشورهای موجود در جدول جستجو میکند.
پیوندهایی که بازیابی می کنید پیوندهای نسبی هستند. تابع urljoin آنها را به پیوندهای مطلق تبدیل می کند. سپس این پیوندها به آرایه all_countries اضافه میشوند که به تابع اصلی برمیگرداند
سپس تابع fetch محتوای HTML را در هر پیوند بهعنوان یک فایل HTML ذخیره میکند. این همان کاری است که این کدها انجام می دهند:
def fetch(link):
res = requests.get(لینک)
با open(link.split("/")[-1]+".html، "wb") به صورت f:
f.write(res.content)
در نهایت، تابع اصلی زمان ذخیره فایلها را در قالب HTML چاپ میکند. در رایانه شخصی ما، 131.22 ثانیه طول کشید. ما آن را در بخش بعدی خواهیم فهمید، جایی که همان برنامه با چندین رشته اجرا می شود. برنامه سریعتر اجرا می شود.
به یاد داشته باشید، همزمانی در مورد ایجاد چندین رشته و اجرای برنامه است. دو راه برای ایجاد رشته وجود دارد – به صورت دستی و با استفاده از کلاس ThreadPoolExecutor.
پس از ایجاد رشته ها به صورت دستی، می توانید از تابع join در همه رشته ها برای روش دستی استفاده کنید. با انجام این کار، متد main منتظر می ماند تا تمام رشته ها اجرای خود را کامل کنند.
در این برنامه، کد را با کلاس ThreadPoolExecutor که بخشی از همزمان است، اجرا می کنیم. ماژول آتی پس اول از همه باید خط زیر را در برنامه بالا قرار دهید.
from concurrent.futures import ThreadPoolExecutorپس از آن، میتوانید حلقه for را که محتوای HTML را در قالب HTML ذخیره میکند به صورت زیر تغییر دهید:
با ThreadPoolExecutor(max_workers=32)
executor.map (واکشی، کلیک کردن)
کد بالا یک مخزن رشته با حداکثر 32 رشته ایجاد می کند. برای هر CPU، پارامتر max_workers متفاوت است و شما باید مقادیر مختلفی را آزمایش کنید. این لزوماً به معنی افزایش تعداد رشتهها در زمان اجرای سریعتر نیست.
بنابراین در رایانه شخصی ما خروجی 15.14 ثانیه تولید میشود که بسیار بهتر از زمانی است که آن را به صورت متوالی اجرا میکنیم. 19659002]بنابراین قبل از اینکه به بخش بعدی برویم، در اینجا کد نهایی برنامه با اجرای همزمان آمده است:
درخواستهای واردات
از واردات bs4 BeautifulSoup
از urllib.parse import urljoin
از concurrent.futures واردات ThreadPoolExecutor
زمان واردات
def get_countries():
کشورها = 'https://en.wikipedia.org/wiki/List_of_national_capitals_by_population'
all_countries = []
پاسخ = requests.get(کشورها)
soup = BeautifulSoup (response.text، "html.parser")
country_pl = soup.select('th .flagicon+ a')
برای link_pl در country_pl:
پیوند = link_pl.get ("href")
پیوند = urljoin (کشورها، پیوند)
all_countries.append(لینک)
بازگشت همه_کشورها
def fetch(لینک):
res = requests.get(لینک)
با open(link.split("/")[-1]+".html، "wb") به صورت f:
f.write(res.content)
def main():
clinks = get_countries()
print(f"مجموع صفحات: {len(clinks)}")
start_time = time.time()
با ThreadPoolExecutor(max_workers=32) به عنوان مجری:
executor.map (واکشی، کلیک کردن)
duration = time.time() -start_time
print(f"دانلود پیوندهای {len(clinks)} در {دوره} ثانیه")
main()
چگونه موازی سازی می تواند خراش دادن وب را سرعت بخشد
اکنون امیدواریم که درک درستی از اجرای همزمان به دست آورده باشید. برای کمک به تجزیه و تحلیل بهتر، بیایید به نحوه عملکرد یک برنامه مشابه در یک محیط چند پردازنده ای با فرآیندهایی که به طور موازی در چندین CPU اجرا می شوند، نگاه کنیم. پایتون متد ()cpu_count را ارائه میکند که تعداد CPUهای دستگاه شما را میشمرد. بدون شک برای تعیین تعداد دقیق وظایفی که می تواند به صورت موازی انجام دهد مفید است.
اکنون باید کد را با حلقه for در اجرای متوالی با این کد جایگزین کنید:
با Pool (cpu_count()) به صورت p. :
p.map (واکشی، کلیک کردن)
پس از اجرای این کد، زمان اجرای کلی 20.10 ثانیه تولید کرد که نسبتاً سریعتر از اجرای متوالی در برنامه اول است. شما ممکن است یک مرور کلی از برنامه نویسی موازی و متوالی داشته باشید—انتخاب استفاده از یکی بر دیگری در درجه اول به سناریوی خاصی که با آن روبرو شده اید بستگی دارد. یک راه حل موازی عالی خواهد بود. امیدواریم از خواندن این مقاله لذت برده باشید. همچنین فراموش نکنید که سایر مقالات مرتبط با اسکراپینگ وب مانند این مقاله را در وبلاگ ما بخوانید.
