
تجزیه داده اصطلاحی است که معمولاً هنگام کار با مقدار زیادی داده به آن برخورد می کنید ، مخصوصاً برای کسانی که داده ها را از وب و همچنین مهندسان نرم افزار می تراشند. با این حال ، تجزیه و تحلیل داده ها موضوعی است که باید در عمق بیشتری مورد بحث قرار گیرد. به عنوان مثال ، تجزیه و تحلیل داده دقیقاً چیست و چگونه آن را در دنیای واقعی پیاده سازی می کنید.
این مقاله به تمام س questionsالات فوق پاسخ می دهد و نمای کلی از اصطلاحات قابل توجه مرتبط با تجزیه داده را ارائه می دهد.
تجزیه و تحلیل چیست؟ میانگین؟
وقتی مقدار زیادی داده از وب تراشیدن استخراج می کنید ، آنها در قالب HTML هستند. متأسفانه ، این برای هر غیر برنامه نویس در قالب قابل خواندن نیست. بنابراین شما باید اطلاعات بیشتری را در مورد داده ها انجام دهید تا آنها را در قالبی قابل خواندن توسط انسان قرار دهد و این امر برای تجزیه و تحلیل دانشمندان داده راحت تر است. تجزیه کننده است که بیشترین تحمل سنگین را در تجزیه انجام می دهد.
تجزیه کننده داده چه کاری انجام می دهد؟
تجزیه کننده داده ها را در یک قالب به داده های شکل دیگر تبدیل می کند. به عنوان مثال ، تجزیه کننده داده های HTML را که از طریق خراشیدن به دست آورده اید به JSON ، CSV و حتی جدول تبدیل می کند تا در قالبی باشد که بتوانید بخوانید و تجزیه و تحلیل کنید. همچنین لازم به ذکر است که تجزیه کننده به هیچ قالب داده خاصی متصل نیست.
تجزیه کننده هر رشته HTML را تجزیه نمی کند زیرا تجزیه کننده خوب داده های مورد نیاز را در برچسب های HTML از بقیه متمایز می کند.
فناوری های مختلف استفاده از تجزیه کننده

همانطور که در بخش قبلی ذکر شد ، از آنجا که تجزیه کننده به یک فناوری خاص وابسته نیست ، طبیعت آن فوق العاده انعطاف پذیر است. بنابراین طیف گسترده ای از فناوری ها از آنها استفاده می کنند:
Scripting Languages- اینها زبانهایی هستند که برای اجرا نیازی به کامپایلر ندارند زیرا بر اساس یک سری دستورات درون یک فایل اجرا می شوند. نمونه های معمول آن PHP ، Python و JavaScript است.
جاوا و سایر زبان های برنامه نویسی- زبان های برنامه نویسی سطح بالا مانند جاوا از یک کامپایلر برای تبدیل کد منبع به زبان اسمبلی استفاده می کنند. تجزیه کننده یکی از اجزای قابل توجه این کامپایلرها است که نمایشی داخلی از کد منبع ایجاد می کند.
HTML و XML- در مورد HTML ، تجزیه کننده متن را در برچسب های HTML مانند عنوان ، عناوین استخراج می کند ، پاراگرافها و غیره. در حالی که تجزیه کننده XML کتابخانه ای است که خواندن و دستکاری اسناد XML را تسهیل می کند.
تجزیه کننده زبانها – تجزیه کننده در زبانهای مدل سازی به توسعه دهندگان ، تحلیلگران و سهامداران اجازه می دهد ساختار سیستم مدلسازی شده را درک کنند.
زبانهای داده ای تعاملی – در پردازش متقابل مقادیر زیادی از داده ها ، از جمله علوم فضایی و فیزیک خورشیدی استفاده می شود.
چرا به تجزیه داده نیاز دارید؟
دلیل اصلی نیاز به تجزیه این است که نهادهای مختلف به داده ها در قالب های مختلف نیاز دارند. بنابراین تجزیه و تحلیل اجازه می دهد داده ها را به گونه ای تبدیل کند که انسان یا در برخی موارد نرم افزار بتواند آن را درک کند. یکی از نمونه های برجسته مورد دوم برنامه های رایانه ای است. اول ، انسانها آنها را در قالبی می نویسند که بتوانند با یک زبان سطح بالا مشابه زبان طبیعی مانند انگلیسی که ما روزانه از آن استفاده می کنیم ، درک کنند. سپس رایانه ها آنها را به شکلی درمورد کد سطح ماشین ترجمه می کنند که کامپیوترها آن را درک می کنند.
تجزیه همچنین برای شرایطی که ارتباط بین دو نرم افزار مختلف مورد نیاز است – به عنوان مثال ، یک سری سازی و بریک کردن یک کلاس ، ضروری است. اصطلاحات تجزیه و تحلیل ساختار
تا این مقطع ، شما مفاهیم اساسی تجزیه داده ها را می دانید. اکنون وقت آن است که مفاهیم مهم مرتبط با تجزیه داده و نحوه کارکرد تجزیه کننده را بررسی کنیم.
اصطلاحات

- عبارات منظم
عبارات منظم مجموعه ای از نویسه ها هستند كه الگوی خاصی را تعریف می كنند. این زبانها بیشتر توسط زبانهای سطح بالا و اسکریپت نویسی برای تأیید آدرس ایمیل یا تاریخ تولد استفاده می شوند. اگرچه آنها برای تجزیه داده ها نامناسب تلقی می شوند ، اما همچنان می توانند برای تجزیه ورودی ساده استفاده شوند. این تصور غلط به این دلیل بوجود می آید که برنامه نویسان خاصی برای هر کار تجزیه و تحلیل از عبارات منظم استفاده می کنند ، حتی زمانی که قرار نیست از آنها استفاده شود. در چنین شرایطی ، نتیجه یک سری عبارات منظم است که با هم هک می شوند.
برای تجزیه برخی زبانهای برنامه نویسی ساده ، که به آنها به عنوان زبانهای معمولی نیز معروفند ، می توانید از عبارات منظم استفاده کنید. با این حال ، این شامل HTML نیست ، که می توانید آن را به عنوان یک زبان ساده در نظر بگیرید. این به این دلیل است که در داخل برچسب های HTML ، با هر تعداد برچسب دلخواه روبرو خواهید شد. همچنین ، با توجه به گرامر خود ، دارای عناصر بازگشتی و تو در تو است که نمی توانید آنها را به عنوان زبان عادی طبقه بندی کنید. بنابراین هر چقدر باهوش باشید نمی توانید آنها را تجزیه کنید.
- Grammars
Grammar مجموعه قوانینی است که یک زبان را به صورت نحوی توصیف می کند. بنابراین ، این فقط برای نحو است و نه از معناشناسی یک زبان. به عبارت دیگر ، دستور زبان به ساختار یک زبان و نه معنای آن اطلاق می شود. مثال زیر را در نظر بگیریم:
HI: "HI"
NAME: [a-zA-z] +
سلام: HI NAME
دو خروجی ممکن برای کد بالا می تواند "HI SARA" باشد یا "کدگذاری HI". تا آنجا که به ساختار زبان مربوط می شود ، هر دو صحیح هستند. با این حال ، در خروجی دوم ، از آنجا که "کدگذاری" نام شخص نیست ، از نظر معنایی نادرست است.
Anatomy of Grammar
مانند فرم Backus-Naur (BNF) . این فرم انواع مختلفی دارد که فرم Backus-Naur Extended است ، و نشان دهنده تکرار است. نوع دیگر BNF فرم افزوده شده Backus-Naur است. هنگام توصیف پروتکل های ارتباطی دو طرفه ، از آن استفاده می شود. به این معنی که می توانید عناصر موجود در سمت راست را جایگزین کنید ، _ بیان. _expression_ می تواند شامل نمادهای پایانی و همچنین نمادهای غیر پایانی باشد.
حال ممکن است شما بپرسید که نمادهای پایانی چیست؟ خوب ، آنها مواردی هستند که به عنوان نماد در هیچ یک از اجزای دستور زبان ظاهر نمی شوند. یک نمونه معمول از یک نماد ترمینال رشته ای از شخصیت ها مانند "برنامه" است.
از آنجا که قاعده ای مانند موارد فوق از نظر فنی تحول بین غیر انتهایی و گروه غیر ترمینال و ترمینال در سمت راست را تعریف می کند ، می توان آن را تولید نامید قاعده.
نوع گرامرها
گرامرها دو نوع دارند و آنها گرامرهای منظم و دستور زبان های بدون زمینه هستند. دستور زبان منظم برای تعریف یک زبان مشترک استفاده می شود. همچنین نوع جدیدتری از گرامر وجود دارد که به عنوان گرامر بیان تجزیه (PEG) شناخته می شود ، زبانهای بدون زمینه را نشان می دهد و همچنین به عنوان دستور زبان های بدون زمینه قدرتمند هستند. به هر حال تفاوت بین این دو نوع به نمادگذاری و نحوه اجرای قوانین بستگی دارد.
روش ساده تری که می توانید بین دو گرامر متمایز کنید ، عبارت _ بیان است ، یا سمت راست قانون می تواند به صورت زیر باشد:
- یک رشته خالی
- یک نماد تک ترمینال
- یک نماد ترمینال با یک نماد غیر ترمینال دنبال می شود.
در واقع ، گفتن این کار آسان تر از انجام است ، زیرا یک ابزار خاص می تواند نمادهای ترمینال بیشتر در یک تعریف سپس می تواند این عبارت را به یک سری صحیح از عبارات تبدیل کند که متعلق به هر یک از موارد فوق است.
بنابراین حتی یک عبارت مبتذل که می نویسید به شکل مناسب تبدیل می شود ، اگرچه با یک زبان طبیعی سازگار نیست. [19659021] اجزای تجزیه کننده
همانطور که تجزیه کننده وظیفه تجزیه و تحلیل یک رشته از نمادها را در یک زبان برنامه نویسی مطابق با قوانین گرامری که ما در حال حاضر بحث کردیم ، می توانیم عملکرد تجزیه کننده را به دو مرحله تقسیم کنیم. به طور معمول به تجزیه کننده دستور داده می شود که داده های ساختاریافته را به صورت برنامه ریزی شده بخواند ، تجزیه و تحلیل کرده و آنها را به یک قالب ساختار یافته تبدیل کند.
دو م majorلفه اصلی تجزیه کننده واژگان و تجزیه و تحلیل نحوی است. علاوه بر این ، برخی از تجزیه کننده ها نیز یک م componentلفه تجزیه و تحلیل معنایی را پیاده سازی می کنند که داده های ساخت یافته را می گیرد و آنها را به صورت مثبت یا منفی ، کامل یا ناقص فیلتر می کند. اگرچه ممکن است تصور کنید این فرآیند روند تجزیه و تحلیل داده ها را بیشتر بهبود می بخشد ، اما همیشه این سناریو نیست.
تجزیه و تحلیل معنایی در بیشتر تجزیه کنندگان به دلیل روشهای مطلوب تحلیل معنایی انسان ساخته نمی شود. بنابراین تجزیه و تحلیل معنایی باید یک گام اضافی باشد ، و اگر قصد دارید آن را انجام دهید ، باید اهداف تجاری شما را تکمیل کند.
بیایید در مورد دو فرایند اصلی تجزیه کننده بحث کنیم.
- تجزیه و تحلیل لغوی
این است توسط Lexar انجام می شود ، که به آن اسکنر یا توکنایزر نیز گفته می شود و نقش آنها تبدیل توالی داده ها یا کاراکترهای ساختاریافته خام به نشانه ها است. اغلب این رشته از نویسه هایی که وارد تجزیه کننده می شوند ، در قالب HTML هستند. سپس تجزیه کننده با استفاده از واحدهای واژگانی ، از جمله کلمات کلیدی ، شناسه ها و جداکننده ها ، نشانه هایی را ایجاد می کند. همزمان تجزیه کننده داده های بی ربط از نظر لغوی را که در بخش مقدماتی لمس کردیم ، نادیده می گیرد. به عنوان مثال ، آنها شامل فضاهای سفید و نظرات در داخل یک سند HTML هستند.
پس از آنکه تجزیه کننده در هنگام فرایند واژگان ، علائم نامربوط را کنار گذاشت ، بقیه مراحل تجزیه و تحلیل با تجزیه و تحلیل نحوی سروکار دارند. تجزیه داده شامل ساخت یک درخت تجزیه است. این بدان معنی است که پس از تجزیه نشانه ها ، تجزیه کننده ها آنها را در یک درخت قرار می دهد. در طی این فرآیند ، نشانه های نامربوط نیز در ساختار لانه سازی خود درخت اسیر می شوند. نشانه های بی ربط شامل پرانتز ، نقطه ویرگول و براکت های مجعد است.
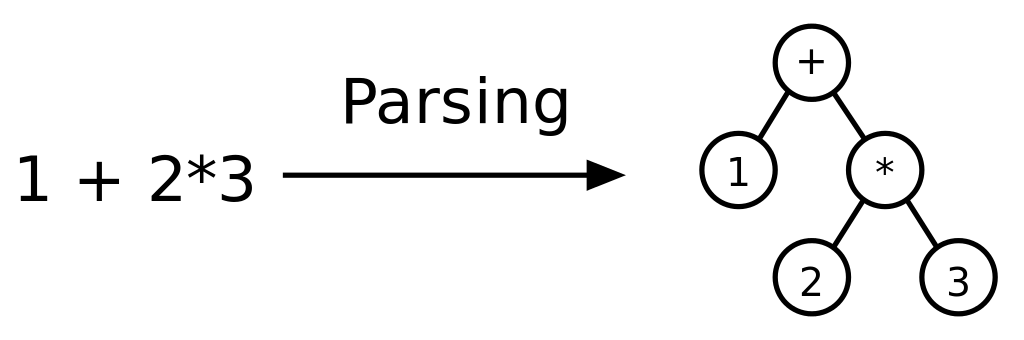
برای اینکه این موضوع را بهتر بفهمید ، بیایید آن را با یک معادله ریاضی ساده نشان دهیم: آنها را به صورت زیر در نشانگرهای زیر قرار دهید: 19659002] 4 => مقدار
- پس از آن درخت تجزیه به شکل زیر ساخته می شود.
اکنون شما درکی از جنبه های اساسی تجزیه کننده پیدا کرده اید. اکنون زمان جنبه هیجان انگیز این است که آیا می خواهید تجزیه کننده خود را بسازید یا یکی از آن را به خارج از کشور برسانید. ابتدا اجازه دهید مزایا و معایب هر یک از روش ها را بررسی کنیم.
مزایای تجزیه کننده داخلی
هنگام ساخت تجزیه کننده داخلی فواید بی شماری برای شما دارد. یکی از مزایای اصلی شامل کنترل بیشتر شما بر روی مشخصات است. علاوه بر این ، از آنجا که تجزیه کننده ها به هیچ یک از قالب های داده محدود نمی شوند ، شما این امکان را دارید که مطابقت با قالب های مختلف داده را قابل تنظیم کنید.
برخی از مزایای قابل توجه دیگر شامل صرفه جویی در هزینه ها و کنترل بر به روزرسانی و نگهداری تجزیه کننده داخلی است.
معایب تجزیه کننده داخلی
تجزیه کننده داخلی بدون مشکلات نیست. یکی از اشکالات قابل توجه این است که وقتی شما کنترل قابل توجهی بر تعمیر و نگهداری ، به روزرسانی و آزمایش آن دارید ، وقت بسیار ارزشمند شما را می گیرد. اشکال دیگر این است که آیا شما می توانید یک سرور قدرتمند بخرید و سریعتر از نیاز خود تجزیه و تحلیل کنید. سرانجام ، شما باید برای ساخت تجزیه کننده و آموزش آموزش در مورد همه کارکنان داخلی خود آموزش دهید.
جوانب تجزیه کننده برون سپاری
هنگامی که تجزیه کننده را برون سپاری کنید ، در هزینه ای که صرف منابع انسانی می کنید صرفه جویی می کند زیرا شرکت خریدار همه وظایف از جمله سرورها و تجزیه کننده را به شما ارائه می دهد. علاوه بر این ، احتمالاً با خطاهای قابل توجهی روبرو خواهید شد زیرا شرکتی که آن را ساخته است احتمالاً قبل از انتشار سناریوها به بازار ، همه سناریوها را آزمایش می کند.
در صورت بروز هرگونه خطا ، پشتیبانی فنی از طرف شرکت وجود خواهد داشت. شما تجزیه کننده را از همچنین وقت کافی را صرفه جویی خواهید کرد زیرا تصمیم گیری در مورد ساخت بهترین تجزیه کننده از طریق برون سپاری حاصل می شود.
معایب تجزیه کننده برون سپاری
اگرچه برون سپاری فواید بی شماری دارد ، اما موارد منفی نیز برای آن وجود دارد. اشکالات عمده به صورت قابل تنظیم بودن و هزینه در می آیند. از آنجا که شرکت تجزیه و تحلیل عملکرد کاملی را ایجاد کرده است ، هزینه بیشتری را متحمل می شود. علاوه بر این ، کنترل کامل شما بر عملکرد تجزیه کننده محدود خواهد شد.
نتیجه گیری
در این مقاله طولانی ، شما در مورد نحوه کارکرد تجزیه کننده ، و به طور کلی روند تجزیه داده ها و اصول آن اطلاعات دارید. تجزیه و تحلیل داده ها یک فرآیند طولانی و پیچیده است. هنگامی که فرصتی برای تجزیه عملی تجزیه و تحلیل داده ها بدست می آورید ، اکنون به دانش کافی در زمینه انجام کارآمد آن مجهز شده اید.
امیدواریم از این دانش به طور مثر استفاده کنید.

